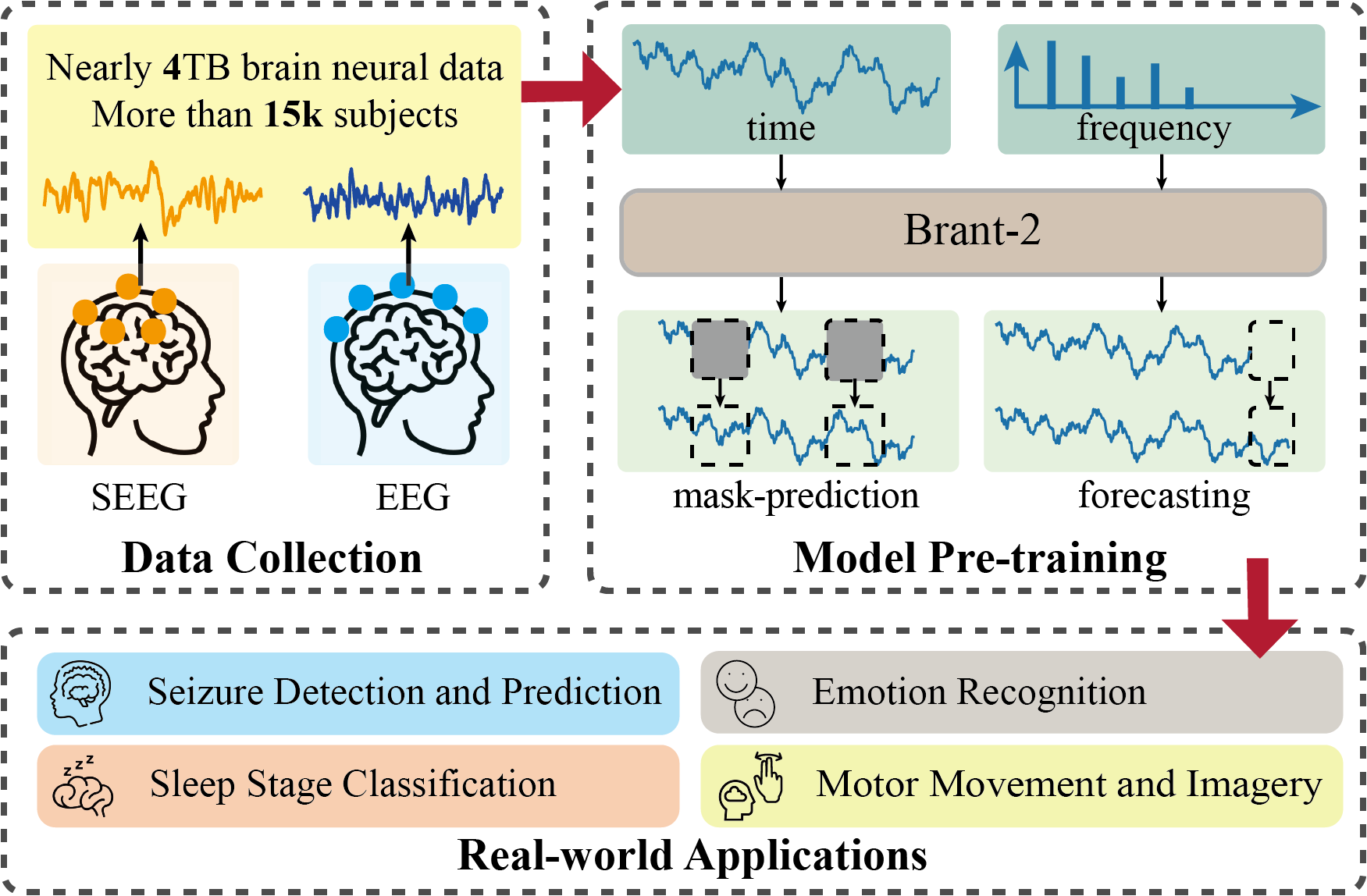
The goal is to establish a universal model for brain signals, enhancing performance in various downstream tasks within the healthcare domain while empowering a quantitative understanding of brain activity in neuroscience.
Starting from a real medical scenario of seizure detection, we automatically identify epileptic waves in intracranial brain signals for medication-resistant patients, expediting the localization of lesions within the brain. Inspired by neuroscience research, we initially model the diffusion patterns of epileptic waves for individual patients (BrainNet, Chen et al., KDD'22). Subsequently, we employ self-supervised learning to capture universal spatiotemporal correlations between signals from different brain regions, facilitating transferability across different patients (MBrain, Cai et al., KDD'23; PPi, Yuan et al., NeurIPS'23).
To establish a foundational model, we initially endeavor to pretrain a foundational model with 500M parameters based on a large volume of intracranial brain signals (Brant, Zhang et al., NeurIPS'23). Subsequently, we integrate EEG into the pretraining corpus, building a foundational model with 1B parameters, thereby generalizing to a broader range of downstream tasks such as sleep staging and emotion recognition (Brant-2, arXiv:2402.10251).
Capitalizing on the robust generalization capabilities of Brant-2, we propose a unified alignment framework (Brant-X) to rapidly adapt Brant-2 to downstream tasks involving rare physiological signals (e.g., EOG/ECG/EMG).
In our pursuit to construct a universal foundational model, we recognize the necessity for a comprehensive dataset encompassing a wide array of domains. Confronted with the rarity of brain signal data, we delve into a diffusion-based model, for the generation of intracranial brain signals (NeuralDiff). Moreover, we innovate to synthesize endless sequences, thereby circumventing the dependence on actual data (InfoBoost, arXiv:2402.00607).
Papers:
(Chen et al., KDD'22),
(Cai et al., KDD'23),
(Yuan et al., NeurIPS'23),
(Zhang et al., NeurIPS'23),
(Zhang et al., KDD'24),
(Brant-2, arXiv:2402.10251),
(InfoBoost, arXiv:2402.00607).
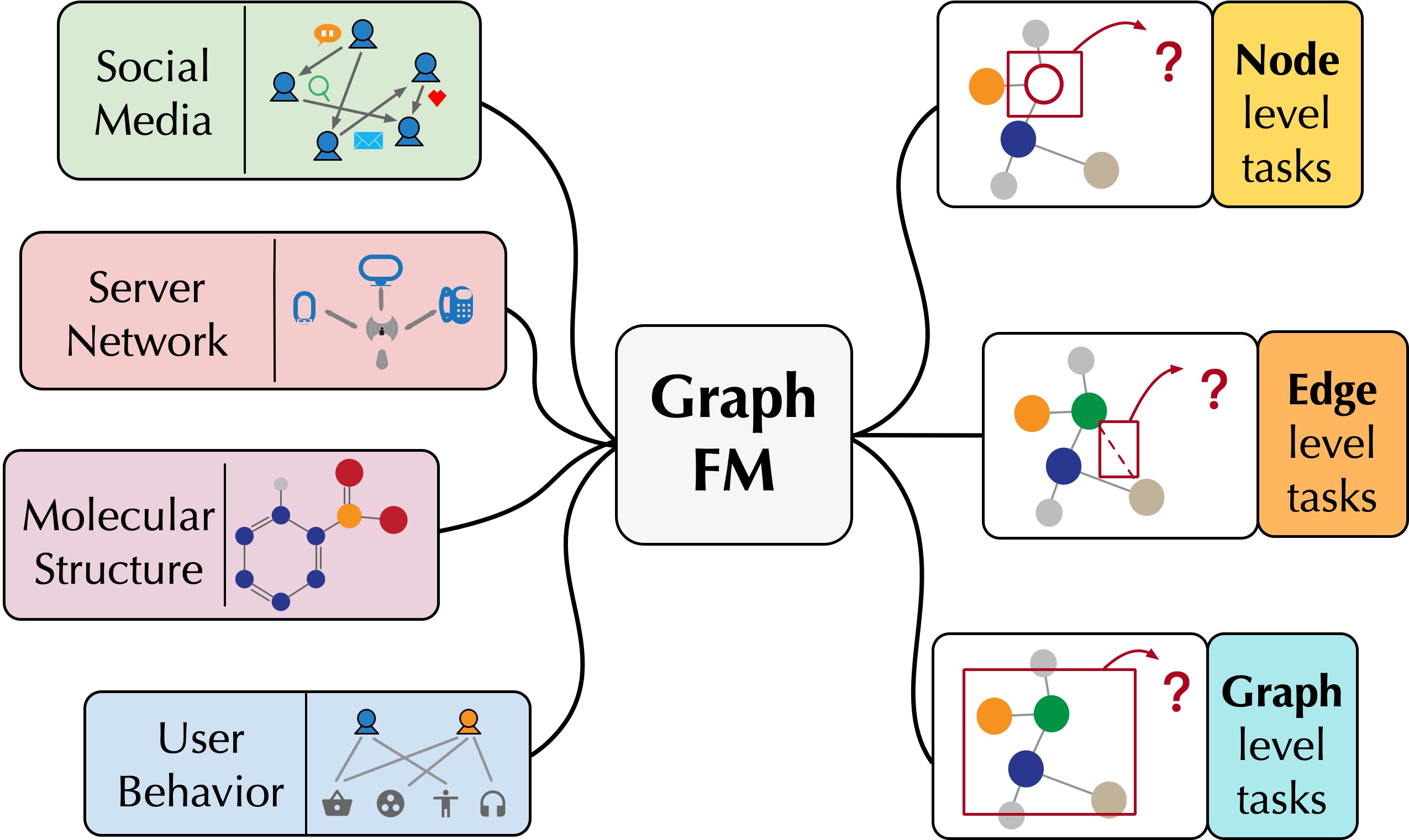
The goal is to pre-train a general graph foundation model using a large corpus of graph data. With appropriate fine-tuning, such a graph foundation model can achieve satisfactory performance across various downstream tasks, showcasing its broad application potential and the numerous challenges it entails.
To achieve this goal, we design base graph models with enhanced expressive capabilities (DropMessage, Fang et al., AAAI'23; PathNet, Sun et al., IJCAI'22) and investigate how to select appropriate pre-training corpora
(W2PGNN, Cao et al., KDD'23; Xu et al., NeurIPS'23). We also conduct an in-depth study on the crucial role of pre-training strategies in the construction of the graph foundation model and analyze existing graph self-supervised methods from a unified perspective (GraphTCM, Fang et al., ICML'24). When adapting the pre-trained graph foundation model to downstream tasks, we explore the intrinsic factors that determine the model's final performance (G-Tuning, Sun et al., AAAI'24; Bridge-Tune, Huang et al., AAAI'24) and design various effective and parameter-efficient adaptation methods (GPF, Fang et al., NeurIPS'23; Huang et al., KDD'24).
In addition, we have released a large-scale dynamic graph financial network pre-training dataset, DGraph (Huang et al., NeurIPS'22), addressing the lack of graph datasets in this field.
Papers:
(Fang et al., AAAI'23),
(Cao et al., KDD'23),
(Xu et al., NeurIPS'23),
(Fang et al., ICML'24),
(Sun et al., AAAI'24),
(Sun et al., IJCAI'22),
(Huang et al., AAAI'24),
(Fang et al., NeurIPS'23),
(Huang et al., NeurIPS'22)
Codes:
[DropMessage]
[PathNet]
[W2PGNN]
[GraphTCM]
[G-Tuning]
[Bridge-Tune]
[GPF]
Dataset:
[DGraph]
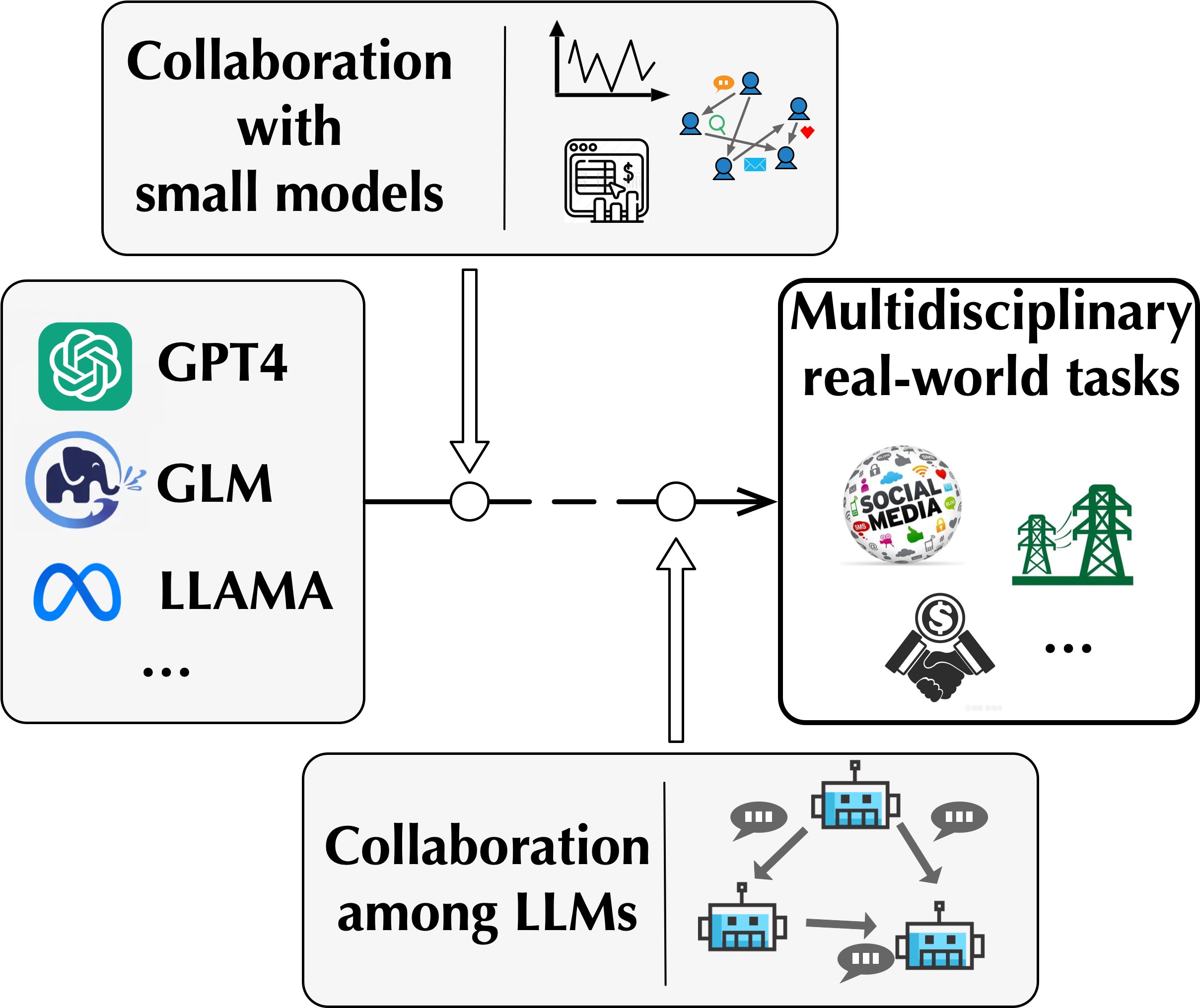
The goal is to enhance the versatility of Large Language Models (LLMs) across specialized domains. Driven by the reality that many real-world applications, such as financial risk management and power grid scheduling, demand a multidisciplinary strategy, we take inspiration from human ingenuity. Humans have a remarkable ability to navigate complex issues by integrating a wide array of expertise through collaborative efforts. With this in mind, we explore the dynamics of LLMs when they collaborate with domain-specific models to tackle challenging real-world problems.
We embark on our journey by examining the synergy between LLMs and Graph Neural Networks (GNNs). GNNs are inherently crafted for processing graph data, a prevalent format in real-world scenarios. We investigate how LLMs can collaborate with GNN to boost its graph reasoning capability (GraphLLM, arXiv:2310.05845). Additionally, we study the
possibility of LLMs and GNNs collaborating through an innovative framework that positions GNNs as a unique class of adapter modules (GraphAdapter, Huang et al., WWW'24). Furthermore, we explore how LLMs can collaborate specialized agents (ETR, Chai et al.,
ACL'24), where a unified generalist framework is built to facilitate seamless integration of multiple expert LLMs.
In addition to our theoretical explorations, we have launched key datasets to assess LLMs in specific domains.
For graph-related tasks, we introduce a new dataset from social media, merging text and graph data (Huang et al., WWW'24).
Additionally, for analyzing LLM-based agents' data analytics capabilities, we publish the InfiAgent-DABench benchmark (InfiAgent, Hu et al., ICML'24).
Papers:
[Chai et al., ACL'24]
(Huang et al., WWW'24),
(Hu et al., ICML'24),
(GraphLLM, arXiv:2310.05845).
Codes:
[ETR],
[GraphLLM],
[GraphAdapter]
Benchmark:
[InfiAgent]
 Yang Yang 杨洋
Yang Yang 杨洋